La revue de web de Kat
Le mot de Kat : Les résultats du moteur de recherche Google sont spammés et de mauvaise qualité selon une étude de ... chercheurs allemands. Google répond : On peut rien y faire, c'est la faute au SEO dopé à l'IA qui pourrit notre moteur.
Par Meera Navlakha le 18 janvier 2024 (mis à jour pour intégrer la réponse de Google)
Vous n'êtes pas le seul, la recherche sur Google a vraiment empiré Une nouvelle étude menée par des chercheurs allemands a révélé que la recherche sur Google est infestée de spam SEO. Votre expérience de la recherche sur Google a-t-elle changé pour le pire ? Vous n'êtes peut-être pas le seul.
Cette révélation provient d'une nouvelle étude menée par des chercheurs allemands de l'université de Leipzig, de l'université Bauhaus de Weimar et du Center for Scalable Data Analytics and Artificial Intelligence (Centre pour l'analyse des données évolutives et l'intelligence artificielle). Les chercheurs ont posé la question "Google devient-il pire ?" en examinant 7 392 requêtes d'évaluation de produits sur Google, Bing et DuckDuckGo pendant un an.
Les chercheurs se sont appuyés sur des rapports indiquant qu'"un torrent de contenu de faible qualité, en particulier pour la recherche de produits, continue de noyer tout type d'information utile dans les résultats de recherche". Un nombre important de résultats trouvés en réponse à des requêtes liées à des produits étaient des "spams de référencement de produits".
La recherche a montré que les sites de spam sont très répandus, apparaissant en haut des classements de Google dans ce qui est une "bataille constante" entre les sites et le moteur de recherche. En d'autres termes, écrivent-ils, "les moteurs de recherche semblent perdre le jeu du chat et de la souris qu'est le spam SEO".
"Le référencement est une bataille constante et nous observons des schémas répétés d'entrée et de sortie de spams dans les résultats, alors que les moteurs de recherche et les ingénieurs en référencement ajustent leurs paramètres à tour de rôle", peut-on lire dans le rapport. Bien que Google, Bing et DuckDuckGo éliminent les spams, les chercheurs affirment que cela n'a qu'un "effet positif temporaire".
Un porte-parole de Google a déclaré à Mashable que l'étude "ne reflète pas la qualité et l'utilité globales de la recherche". Il a souligné que l'étude ne portait que sur un ensemble restreint de requêtes, à savoir la recherche de produits.
"Cette étude ne s'intéresse qu'au contenu des critiques de produits et ne reflète pas la qualité et l'utilité globales de la recherche pour les milliards de requêtes que nous recevons chaque jour. Nous avons apporté des améliorations spécifiques pour remédier à ces problèmes, et l'étude elle-même souligne que Google s'est amélioré au cours de l'année écoulée et que ses performances sont supérieures à celles des autres moteurs de recherche. De manière plus générale, de nombreux tiers ont mesuré les résultats des moteurs de recherche pour d'autres types de requêtes et ont constaté que Google était d'une qualité nettement supérieure aux autres", a déclaré le porte-parole.
L'étude en question a montré que les résultats de Google se sont améliorés "dans une certaine mesure" entre le début et la fin de l'expérience des chercheurs. Néanmoins, ils ont constaté "une tendance générale à la baisse de la qualité des textes dans les trois moteurs de recherche". Avec la présence de spam généré par l'IA, la situation ne peut que s'aggraver, prévient l'étude.
"Nous concluons que le spam contradictoire dynamique sous la forme d'un contenu commercial de faible qualité produit en masse mérite plus d'attention", écrivent les chercheurs.
Comme le rapporte 404Media, d'autres chercheurs ont remarqué que Google était inondé de spam. Search Engine Journal, par exemple, a déclaré qu'en décembre 2023, Google a été submergé par une attaque massive de spam qui a duré plusieurs jours.


C’est par l’intermédiaire d’une réponse à une question écrite du député Modem Philippe Latombe que le ministère de l’Éducation Nationale officialise publiquement l’arrêt dans les établissements scolaires du déploiement ou extension de Microsoft Office 365, « ainsi que celle de Google, qui seraient contraires au RGPD ».
À l’origine, Philippe Latombe pointait dans sa question que l’offre gratuite de Microsoft « s'apparente à une forme ultime de dumping et à de la concurrence déloyale. Il semble par ailleurs qu'aucun appel d'offres n'ait eu lieu ».
Dans sa réponse, le ministère explique que les offres gratuites sont «exclues du champ de la commande publique » même s’il concède qu' « il est vraisemblable que la mise à disposition gratuite des établissements scolaires d'une suite bureautique vise à inciter un public qui aurait été accoutumé à l'utilisation de ces outils à souscrire par la suite à la version payante de son offre ». Mais il affirme avoir informé en octobre 2021 les recteurs de région académique et d'académie de la doctrine « cloud au centre » du gouvernement et des positions de la Dinum et de la CNIL sur le sujet.
Perfidement, la réponse du ministère souligne aussi que le code de l’éducation prévoit que ce sont les collectivités territoriales (les communes pour les écoles, les départements pour les collèges et les régions pour les lycées) qui doivent assurer « l'acquisition et la maintenance des infrastructures et des équipements, dont les matériels informatiques et les logiciels prévus pour leur mise en service, nécessaires à l'enseignement et aux échanges entre les membres de la communauté éducative sont à [leur] charge ».
Les applications « Messages » et « Téléphone » de Google, installées sur plus d'un milliard de smartphones, enregistrent l'activité de l'utilisateur et envoient ces données sur les serveurs de la firme. Les utilisateurs ne sont pas informés de cette collecte, qui ne respecterait pas le RGPD, et n'ont aucun moyen de s'y opposer.
Les utilisateurs d'Android sont habitués aux alertes concernant de fausses applications qui collectent leurs données. Cependant, cette fois ce sont deux applications légitimes préinstallées sur les versions récentes d'Android qui envoient des informations personnelles à Google...
Le problème a été découvert par Douglas Leith, professeur d'informatique au Trinity College de Dublin. Ce sont deux applications de Google qui sont mises en cause, à savoir Messages (com.google.android.apps.messaging) et Téléphone (com.google.android.dialer). À chaque SMS envoyé ou reçu, Messages envoie à Google un rapport qui inclut l'heure et une empreinte numérique du message. Ces données sont transmises à travers le service d'enregistrement Clearcut de Google Play ainsi que le service Firebase Analytics.
Google peut croiser les informations pour identifier l’émetteur et le destinataire
L'appli utilise la fonction de hachage SHA-256 pour créer une empreinte tronquée, ce qui est censé éviter de dévoiler le contenu du message. Toutefois, cela suffirait à Google pour faire le lien entre l'expéditeur et le destinataire. L'application Téléphone envoie des rapports similaires, avec l'heure et la durée des appels reçus ou émis. De plus, quand la protection contre les appels indésirables est activée, ce qui est le cas par défaut, l'appareil transmet également le numéro appelant aux serveurs de Google.
Graphique sur le lien entre les données collectées et l’identité réelle, via un identifiant Android, lié aux identifiants de l’appareil et de la carte SIM, ainsi qu’au compte Google, lui-même lié au numéro de téléphone et cartes bancaires. © Douglas Leith
Graphique sur le lien entre les données collectées et l’identité réelle, via un identifiant Android, lié aux identifiants de l’appareil et de la carte SIM, ainsi qu’au compte Google, lui-même lié au numéro de téléphone et cartes bancaires. © Douglas Leith
Les deux applis envoient également des informations détaillées sur leur utilisation, par exemple lorsque l'utilisateur affiche un message ou effectue une recherche dans ses conversations. Google n'informe à aucun moment l'utilisateur de la collecte de données et n'offre aucun moyen de s’y opposer. Le professeur met également en doute la conformité des applications avec le règlement général sur la protection des données (RGPD). Cette collecte ne respecterait pas les trois principes de base concernant l'anonymat, le consentement et un intérêt légitime.
Un fonctionnement particulièrement opaque
Après avoir signalé à Google ces problèmes, la firme a répondu en indiquant effectuer quelques changements. Les utilisateurs seront notifiés qu'ils utilisent une application Google avec un lien vers la politique de confidentialité. Messages ne collectera plus le numéro d'expéditeur, le code ICCID de la carte SIM, ainsi que l'empreinte des SMS. Les deux applications n'enregistreront plus les évènements liés aux appels dans Firebase Analytics. La collecte de données utilisera un identifiant temporaire plutôt que l'identifiant Android permanent. Enfin, Google informera plus explicitement les utilisateurs lorsque la fonction de protection contre les appels indésirables sera activée, et cherche actuellement comment utiliser moins d'informations ou des données plus anonymes.
Le professeur a également indiqué que Google compte ajouter à Messages une option pour refuser la collecte d’informations. Toutefois, celle-ci ne couvrirait pas ce que la firme considère comme données « essentielles ». Il s'agit d'une des premières études sur les données personnelles transmises par les services Google Play, qui restent largement opaques et pourraient cacher bien d'autres surprises...
La CNIL[1] a mis en demeure un éditeur pour avoir collecté des données à caractère personnel sur les visiteurs de son site Internet à l’aide du module Google Analytics.
En intégrant ce module Google Analytics à son site Internet, l’éditeur donnait la consigne aux navigateurs de ses visiteurs d’envoyer des informations à Google. Ces informations contenaient notamment l’adresse de la page visitée, l’éventuel page précédemment visitée (« Referer »), l’heure de la visite, l’adresse IP du visiteur et des informations sur son appareil. Ces informations pouvaient aussi contenir l’identifiant unique qui était attribué par Google à l’internaute et stocké dans un cookie et/ou l’identifiant interne que l’éditeur du site avait attribué à l’internaute, si ce dernier était connecté à son espace personnel. Le numéro de commande était aussi présent si la personne avait passé commande sur le site.
Toutes ces informations permettaient à l’éditeur de mesurer l’audience de son site Internet avec précision, mais aussi de détecter d’éventuelles erreurs et de mesurer ou d’optimiser l’efficacité ses campagnes publicitaires.
En premier lieu, la CNIL a considéré que les données collectées par ce module Google Analytics étaient des données à caractère personnel, car elles étaient associées à un identifiant unique et/ou composées de données qui pouvaient permettre d’identifier les visiteurs ou de les différencier de façon significative. La Commission a donc estimé que les exigences du RGPD[2] devaient être respectées.
Ensuite, la CNIL a rappelé que les transferts de données vers un pays n’appartenant pas à l’Union européenne étaient autorisés uniquement si « le niveau de protection des personnes physiques garanti par le [RGPD] n[’est] pas compromis »[3]. Un tel niveau de protection peut être obtenu :
- si le pays de destination bénéficie d’une « décision d’adéquation »[4], c’est-à-dire une décision émanant des autorités attestation de la conformité du pays en matière de protection des données ; ou
- si l’organisme de destination justifie que les mesures prises et la législation du pays permettent d’assurer un niveau de protection suffisant.
Les données issues de Google Analytics sont transférées vers les États-Unis. Ce pays ne bénéficie plus d’une décision d’adéquation depuis l’arrêt[5] « Shrems II » du 16 juillet 2020 de la Cour de justice de l’Union européenne (CJUE) en raison de la surveillance de masse réalisée par les services gouvernementaux américains. Ces programmes de surveillance obligent notamment la société Google à fournir au gouvernement américain les données à caractère personnelle qu’elle possède ou les clés de chiffrement qu’elle utilise.
En l’absence d’une décision d’adéquation, l’éditeur du site et la société Google avaient recourru à des « clauses contractuelles types », c’est-à-dire un rapport détaillé justifiant un niveau de protection suffisant. La CNIL a cependant considéré, comme l’avait déjà fait la CJUE dans son arrêt cité précédemment, qu’un tel document ne permettait pas, à lui seul, d’apporter une protection contre les programmes de surveillance américain, car la société Google ne pouvait pas aller à l’encontre des lois de son pays. Des mesures additionnelles devaient donc être prises par l’éditeur et/ou Google.
Des mesures organisationnelles ont été prises par Google, comme la publication d’un rapport de transparence et la publication d’une politique de gestion des demandes d’accès gouvernementales, mais la Commission a estimé que ces mesures ne permettent pas « concrètement d’empêcher ou de réduire l’accès des services de renseignement américains ».
Des mesures techniques ont aussi été prises par Google, comme la pseudo « anonymisation »[6] des adresses IPs, mais la CNIL a estimé qu’elles « ne sont pas efficaces », car « aucune d’entre elles n’empêche les services de renseignement américain d’accéder aux données en cause ne ne rendent cet accès ineffectif ».
En l’absence d’une protection des données adéquate, la CNIL a, par conséquent, estimé que les transferts effectué par l’éditeur vers les serveurs de Google situés aux États-Unis étaient illégaux.
La CNIL a mis en demeure le site de mettre en conformité les traitements de données associés à Google Analytrics ou, si ce n’est pas possible, de retirer le module Google Analytics.
Concernant le nom de l’éditeur mis en cause, la CNIL a décidé de ne pas rendre public son nom pour des raisons que j’ignore. Il est cependant fort probable que la société soit Decathlon, Auchan ou Sephora étant donné que cette décision est la conséquence de plaintes[7] déposées par l’association militante NOYB[8].
Concernant la décision elle même, même si c’est la première fois que la CNIL prend publiquement position sur Google Analytics, ce n’est ni une surprise, ni une révolution. Depuis l’invalidation de l’accord avec les États-Unis en juillet 2020, tous les acteurs s’intéressant de près à la protection des données savent que les transferts de données vers les USA étaient, au mieux, très douteux. De plus, la CNIL n’est pas la première autorité de protection des données européenne à avoir statué dans ce sens. L’autorité autrichienne avait fait de même[9] trois mois plus tôt.
Cette décision a le mérite de mettre les choses au clair. Les organismes ne peuvent désormais plus prétendre un éventuel flou juridique. Google Analytics doit être retiré.
Notes et références
CNIL : Commission Nationale de l’Informatique et des Libertés (cnil.fr).
RGPD : Règlement Général sur la Protection des Données (Règlement (UE) 2016/679).
Le RGPD autorise des transferts de données vers des pays tiers si « le niveau de protection des personnes physiques garanti par le [RGPD] n[’est] pas compromis » (source : RGPD, article 44).
Un transfert de données à caractère vers un pays tiers peut être réalisé si une décision d’adéquation existe pour ce pays (source : RGPD, article 45). Une telle décision existe, par exemple, pour le Royaume-Uni.
La Cour de justice de l’Union européenne (CJUE) invalide le « bouclier de protection des données UE-États-Unis » dans un arrêt du 16 juillet 2020 (source : CJUE, C-311/18, 16 juillet 2020, Shrems II).
La solution Google Analytics propose une option permettant d’« anonymiser » les adresses IP des internautes. Cette opération est toutefois réalisée par Google après que le transfert de données vers les États-Unis ait lieu.
L’association NOYB a déposé des plaintes contre de nombreux organismes suite à des transferts de données personnelles vers les États-Unis jugés illicites. Six entreprises francaises sont concernées. Trois d’entre elles concernent Google Analytics : Decathlon, Auchan et Sephora (source : noyb.eu).
NOYB - European Center for Digital Rights : (noyb.eu).
L’autorité autrichienne a décidé, décembre 2021, que les transferts de données réalisés par Google Analytics étaient illicites (source : noyb.eu, en allemand) (source 2 : gdprhub.eu, en anglais).
Ce n’est pas forcément la question la plus soulevée dans la sphère SEO, mais nous voulions déterminer dans cet article si le choix de telle ou telle police web pouvait avoir un impact sur votre SEO.
Peut-être vous-êtes-vous déjà demandés si l’utilisation d’une police web personnalisée ou une Google Font, avait une incidence négative comme positive votre visibilité organique. Pour lever le voile sur ce sujet, nous avons décidé de nous replonger dans les déclarations passées de notre ami John Mueller, Webmaster Trends Analyst chez Google.
En d’autres mots, il s’agit de savoir si Google prenait en compte le choix de la police web pour juger de la qualité de votre contenu, par exemple si une police personnalisée conduisait Google à considérer le contenu comme moins pertinent que des qu’un même contenu utilisant d’autres types de web fonts.
Ce que dit Google
Cette question avait été posée à John Mueller en 2017 lors de la vidéo Webmaster Office Hours ci-dessous.
Le cadre de chez Google affirme que le choix de la police d’écriture n’a pas d’impact sur votre référencement. Du moment que Google peut explorer la page et voir le contenu, l’analyse fonctionnera normalement.
La seule situation où John indique que cela pourrait être un peu délicat est si vous utilisez des images au lieu de texte sur une page. Ok, Google fait de l’OCR (Optical Character Recognition : processus de convertir une image en texte) sur les images, mais cela reste un procédé nouveau qui n’est pas pleinement sollicité pour l’indexation des pages web (cela exige beaucoup trop de ressources).
Impact sur le temps de chargement
Le même sujet a été abordé sur Twitter en 2020. Toujours auprès de John Mueller. Cette fois-ci, la question initiale était de savoir si le choix de sa police avait un impact sur les performances de vitesse du site, puis de savoir s’il y avait des polices recommandées par Google.
Les réponses de John Mueller :
1 - Tous les éléments qui composent une page web, comme la police, ont un impact sur la vitesse de chargement.
2 - Le choix de la police n’a pas d’importance pour le SEO.
Ces deux réponses sont contradictoires puisque le temps de chargement est considéré comme un facteur de ranking SEO. Ainsi, si votre police web impacte le temps de chargement, elle influence indirectement votre SEO.
Bon ok, ce n’est pas nouveau que la police impacte le temps de chargement, c’était d’ailleurs un point majeur soulevé dans notre article sur l’optimisation de votre vitesse de site sous WordPress.
Par conséquent, si vous utilisez une police personnalisée parce que vous voulez mettre en avant votre branding, faites attention à ce que cette dernière n’impacte pas trop vos performances. Surtout avec l’introduction des Core Web Vitals en tant que facteurs de positionnement SEO.
Impact sur l’expérience utilisateur
Évidemment, si vous optez pour des polices web personnalisées totalement illisibles, cela aura un réel impact sur la compréhension qu’auront les visiteurs du contenu de votre site. Veuillez donc à ne pas trop en faire et à trouver l’équilibre entre branding et expérience de navigation.
Mais améliorer l’expérience utilisateur signifie aussi que chaque milliseconde compte. De ce fait, il existe de nombreuses façons d’améliorer la vitesse, comme l’optimisation des images et des polices de caractères web.
Commençons par une note positive : il est facile d’adopter une belle typographie gratuitement pour votre site comme vous pouvez en trouver dans les magazines papier. Des sociétés comme Fontawesome, Google et Adobe proposent énormément de polices gratuites qui vous permettront de construire votre site selon votre image. Cependant, un grand nombre auront impact drastique sur la vitesse de vos pages… pouvant vous faire perdre de précieuses secondes et chuter votre score sur PageSpeed Insights.
Voyons donc ensemble comment ces satanés polices web peuvent autant impacter votre temps de chargement en se focalisant sur les polices Google.
Le problème des polices Google
Les Google Fonts peuvent représenter plusieurs problèmes pour vos performances de site. Mais pas que…
Combien de requêtes HTTP les polices effectuent-elles ?
Lorsque votre site est en train de charger sur un navigateur, vous avez peut-être remarqué des messages dans la barre d’état tels que « connecting to fonts.gstatic.com » ou « waiting for fonts.googleapis.com ». Il s’agit du navigateur qui télécharge la police sur laquelle votre site repose à partir de serveurs qui hébergent ces polices.
Pour analyser ce processus de plus près, il suffit de se rendre sur des sites de mesure de vitesse de page tels que GTmetrix ou Pingdom et de tester votre URL. Il y a de fortes chances que vous soyez surpris par le nombre de requêtes que votre site nécessite pour télécharger des fichiers de polices. Mais… attendez deux p’tites secondes… ces polices ne sont-elles pas transférées à partir d’un Google Cloud super méga rapide ?!!
Existe-t-il un CDN pour les polices ?
Oui, les polices web sont fournies par le CDN de Google. Google a optimisé et continue d’optimiser ces fichiers pour un transfert plus rapide. Néanmoins, il s’agit de demandes supplémentaires de données supplémentaires dont la plupart des sites et blogs peuvent se passer. Les néo webmasters commencent souvent avec un hébergement mutualisé chez OVH, et souvent avec un ensemble de plugins redondants qui alourdissent les performances globales de leur site. Dans la plupart des cas, les fichiers de polices web ne font que s’ajouter à la masse.
Quel est le poids des polices web ?
La taille typique d’un fichier de police est de 35-50ko. Cependant, selon la façon dont votre site est développé, il peut nécessiter plusieurs fichiers de polices ou parfois, même un seul fichier de police peut atteindre un poids de quelques mégaoctets. Cela s’explique par le fait qu’un site peut utiliser plus d’une langue, nécessiter plusieurs formats de fichiers ou devoir être disponible en mode hors ligne. Parfois, les thèmes et les plugins qui utilisent les Google Web Fonts font plusieurs demandes pour la même ressource. Pire encore, votre site peut obliger un visiteur à télécharger des éléments qui ne sont jamais utilisés. La plupart du temps, les visiteurs de votre site peuvent se passer de tout cela.
Du coup, une question légitime que l’on pourrait se poser serait de savoir si la mise en cache avait un impact ? Un navigateur ne va-t-il pas stocker ces polices pour une utilisation ultérieure ? La réponse courte : pas tout.
Quid de la mise en cache des polices Google ?
La mise en cache du navigateur ne permet d’accélérer que les visites répétées, et non les premières visites. Pour les visiteurs réguliers, le webmaster du site a le pouvoir de définir la durée pendant laquelle le navigateur doit mettre en cache une ressource localement. Vous pouvez fixer une date d’expiration lointaine (d’un mois ou plus) pour les ressources statiques telles que les images, etc… mais pas pour tout ! En effet, pour les ressources fournies par des tiers, comme Facebook ou Google, le propriétaire du site n’a aucun contrôle. Leur date d’expiration est fixée par les sites qui les fournissent.
Alors que les fichiers de polices de base peuvent avoir une date d’expiration lointaine, les ressources de style liées aux polices ont une date d’expiration de seulement 24h00 en général. Ainsi, lorsqu’un fichier de police a été modifié et qu’un abonné email clique sur le lien d’une newsletter pour lire votre dernier article, ce visiteur fidèle devra télécharger à nouveau toute la police web requise. Inutile de dire que si votre abonné dispose d’une connexion internet pourrie, vous ne l’aidez pas.
Alors, pourquoi ne pas simplement fournir les polices à partir de votre site et de contrôler l’expiration du cache du navigateur ?
Peut-on charger les polices Google en local ?
Les polices web étant OpenSource, vous pouvez les héberger localement sur votre site, réduire le nombre de requêtes HTTP et contrôler l’expiration du cache. Il existe des plugins gratuits pour vous aider à y parvenir. Toutefois, Google déconseille cette pratique. Cela m’amène à poser la question suivante : pourquoi Google adopterait-il une pratique aussi gourmande en termes de ressources, puis déconseillerait dans le même temps une solution permettant de consommer moins et d’optimiser les performances ?
La raison officielle invoquée par la firme de Mountain View est qu’il héberge et fournit les polices afin que vous ayez les plus récentes et les plus optimisées à disposition pour votre site web. Cependant, la vérité se cache peut-être ailleurs…
Les polices Google portent-elles atteinte à la vie privée ?
Quelques pays, comme la Chine, bloquent l’accès à aux serveurs Google, ce qui signifie que les sites utilisant les Google Fonts n’auront pas la même apparence partout dans le monde. De nombreuses autres personnes ont fait part de leurs inquiétudes quant à la confidentialité des données liées aux polices Google, en particulier dans le sillage de la mise en œuvre de la politique européenne RGPD. En effet, en fournissant la police de votre site, Google a un accès direct à ses entrailles. Pour vous faire une idée, jetez un œil à la quantité gargantuesque de données collectées par Google à travers ses polices en consultant les statistiques du site Google Font Analytics.
Les Google Fonts seront-elles toujours gratuites ?
Les polices web représentent un pilier essentiel pour le secteur des éditeurs. La capture à grande échelle des données d’utilisation de ses polices peut potentiellement aider Google à créer un modèle freemium classant les polices gratuites et premium afin de convaincre les navigateurs (tels que Firefox, Safari ou Internet Explorer) d’inclure certaines de ces polices en tant qu’option native dans leurs futures versions. Autre possibilité, l’API Google Fonts pourrait suivre le chemin de l’API de Google Maps, qui exige désormais des propriétaires de sites qu’ils fournissent des informations de carte bancaire pour pouvoir l’utiliser.
Google propose Google Fonts : des polices d’écritures à utiliser pour votre site web, dans le CSS.
Seulement ils sont bien malin : le code CSS prêt-à-utiliser que vous devez mettre dans votre code contient le lien du fichier de la police d’écriture qui se trouve sur leur serveur. Voilà la marche à suivre pour récupérer manuellement le fichier et le placer en local, chez vous.
Je vais faire l’exemple avec une police d’écriture au hasard.
Rendez-vous sur google.com/fonts. Choisissez la police que vous voulez, puis cliquez sur « quick-use » :
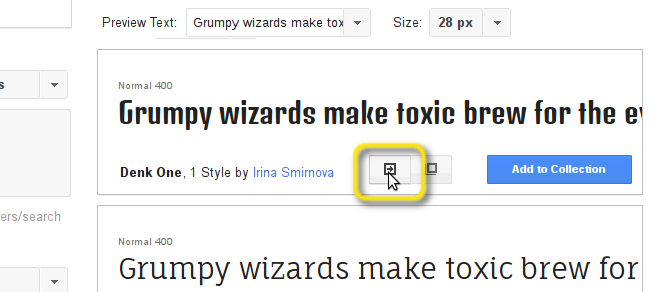
Descendez un peu en bas dans la page et récupérez le lien vers le fichier CSS :
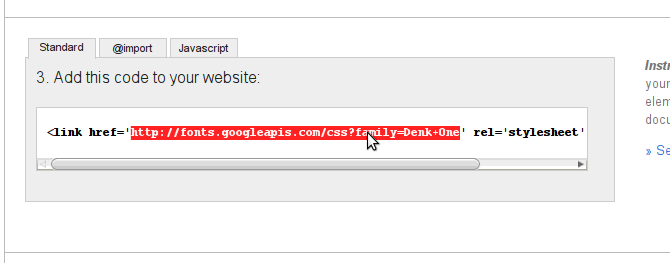
Ouvrez ce lien dans votre navigateur.
Vous pouvez déjà copier tout le code dans votre CSS. Il suffit juste de récupérer le lien vers le fichier de la police (fichier .woff).

Téléchargez le fichier .woff et enregistrez le dans votre projet.
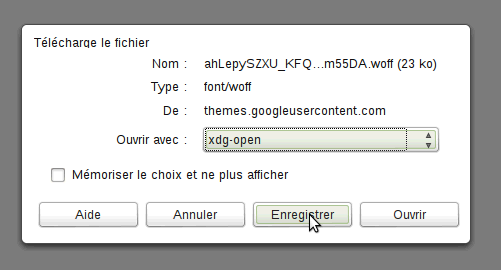
Il ne reste alors plus qu’à changer le lien de la police dans le code CSS, pour qu’il utilise le fichier .woff local et pas via le site de Google.
Voilà, c’est tout.
L’avantage d’avoir le fichier de la police chez soi :
Pas de traçage possible par Google
Votre site reste indépendant : si Google ferme son service (il le fera un jour) votre CSS fonctionnera quand même.Désavantages :
Le fichier de la police sera téléchargé depuis votre site, donc consommera votre bande passante.
Si un autre site web quelque part utilise la même police, le navigateur le téléchargera deux fois, alors qu’il ne le fait qu’une seule fois si les deux utilisent le service de Google.
Cette astuce s’inscrit dans ma politique d’un site 100% indépendant sur le plan technique. Il n’y a aucun fichier (image, script…) utilisé dans mes pages qui soit hébergé ailleurs que chez moi.
L’utilisation de Google Analytics viole le droit européen, juge l’autorité autrichienne de protection des données. L’autorité autrichienne de protection des données a décidé que l’utilisation de Google Analytics violait le règlement général sur la protection des données (RGPD). D’autres États membres de l’UE pourraient lui emboîter le pas, car les régulateurs coopèrent étroitement au sein d’une cellule spéciale du Comité européen de la protection des données.
La décision est fondée sur un certain nombre de plaintes déposées par l’ONG autrichienne noyb à la suite de l’arrêt « Schrems II » de la Cour de justice de l’Union européenne. La CJUE a jugé que l’accord de transfert de données entre les États-Unis et l’Union européenne, le « Privacy Shield », n’était pas conforme à la législation européenne sur la protection des données et a annulé l’accord en 2020, ce qui a rendu illégaux la plupart des transferts de données vers les États-Unis.
Toutefois, Google a partiellement ignoré cette décision. Au cours de la procédure, le géant de la technologie a admis que « toutes les données collectées par Google Analytics […] sont hébergées (c’est-à-dire stockées et traitées ultérieurement) aux États-Unis », ce qui inclut les utilisateurs européens.
Comme de nombreuses entreprises de l’UE utilisent Google Analytics, beaucoup ont transmis leurs données à Google, permettant ainsi que leurs données soient traitées aux États-Unis.
L’autorité autrichienne de protection des données vient de décider que ce comportement constitue une violation de la législation européenne.
« Au lieu d’adapter les services pour qu’ils soient conformes au RGPD, les entreprises américaines ont essayé d’ajouter simplement un texte à leurs politiques de confidentialité et d’ignorer la Cour de justice. De nombreuses entreprises de l’UE ont suivi le mouvement au lieu de se tourner vers des options légales », a déclaré Max Schrems, président honoraire de noyb, dans un communiqué.
« Cela fait maintenant un an et demi que la Cour de justice l’a confirmé une deuxième fois, il est donc plus que temps que la loi soit également appliquée », a ajouté M. Schrems.
La décision des autorités autrichiennes n’est que la première des 101 plaintes que noyb a déposées dans presque tous les pays de l’UE. L’ONG s’attend à ce que « des décisions similaires tombent progressivement dans la plupart des États membres de l’UE », a déclaré M. Schrems.
Mardi, le contrôleur européen de la protection des données a déjà rendu une décision similaire, soulignant que l’utilisation de Google Analytics par le Parlement européen violait le RGPD.
(Oliver Noyan | EURACTIV Allemagne)
L'application de cartographie Google Maps affiche désormais une alerte pour demander aux utilisateurs de partager leurs données en échange de ses facultés de navigation.
Que ce soit sur Android ou iOS, l'application Google Maps affiche désormais un message invitant l'utilisateur à autoriser la collecte de vos données pour pouvoir exploiter certaines des fonctions de navigation. Sans cela, plusieurs options de navigation en temps réel ne seront pas fonctionnelles. Il faut dire que l'application de cartographie réalise une collecte abondante de données, avec notamment les relevés GPS, pour établir les conditions de circulation et les afficher en temps réel ou les prédire grâce à l’analyse statistique. Une précision de plus en plus redoutable qui repose sur un milliard de kilomètres collectés chaque jour sur la planète grâce à l'application Google Maps utilisé par bon nombre de conducteurs.
Il faut payer de sa personne pour se faire guider !
Pour le moment, le message ne s'affiche que chez certains utilisateurs localisés aux États-Unis. En annulant ces nouvelles conditions d'utilisation, sans la collecte de ces données, l'application ne délivrera plus le suivi de navigation à la façon d'un GPS avec les instructions locales. Le géant d'Internet souligne que les données récupérées ne sont aucunement nominatives et associées à votre compte Google.
Hormis cette nouvelle nécessité d'accorder cette autorisation à Google, il n'y aurait aucun changement par rapport à avant. Autrement dit, depuis toujours, l'application collectait les données en question.
La Cnil donne un coup de pied dans la fourmilière : interrogée sur l'emploi d'outils collaboratifs américains, l'autorité administrative française estime qu'il faut s'en passer et opter pour des solutions françaises ou européennes.
Les outils Framasoft plutôt que la suite bureautique de Google Docs pour les élèves qui poursuivent leurs études après le Bac ? Si la Commission nationale de l’informatique et des libertés (Cnil) ne va pas jusqu’à formuler une telle recommandation, le sens de son message est toutefois limpide : il est préférable de délaisser les outils américains pour l’enseignement supérieur et la recherche.
C’est en effet ce qui transparait dans une prise de parole datée du 27 mai 2021. La Cnil répondait alors aux sollicitations de la Conférence des grandes écoles et la Conférence des présidents d’université sur l’évolution du cadre juridique européen et ses effets que cela peut avoir sur les conditions stockage et de circulation des données qui sont produites, collectées et manipulées via ces outils de travail.
Pourquoi la Cnil formule ce conseil ?
Cet appel de la Cnil ne vient pas de nulle part : il tient compte d’une réalité juridique avec l’invalidation du Privacy Shield par la Cour de justice de l’Union européenne, à l’été 2020. Or ce cadre, qui remplaçait le Safe Harbor, un mécanisme similaire qui a aussi été détruit, servait à encadrer le transfert des données des internautes en Europe vers les États-Unis, là où figurent de nombreux services en ligne.
La Cour a considéré qu’il n’existe en fait aucune garantie juridique pour des personnes non américaines pouvant être visées par les programmes de surveillance américains. Or, le Privacy Shield était censé être conforme aux standards européens. En clair, il y a un conflit manifeste entre le droit européen et le droit américain. Dès lors, la légalité de ces transferts est remise en question.
Considérant ce verdict majeur, véritable séisme juridique au niveau européen, mais aussi les documents qui lui ont été transmis, la Cnil relève que « dans certains cas, des transferts de données personnelles vers les États-Unis dans le cadre de l’utilisation des suites collaboratives pour l’éducation » surviennent, et cela pour beaucoup de monde : étudiants, chercheurs, enseignants, personnels administratifs.
Ce n’est pas tout : des informations encore plus critiques peuvent être en jeu, comme des données de santé (qui sont des données sensibles devant bénéficier d’un plus haut degré de protection ), des données particulières (relatives à des mineurs) et des données pouvant impliquer des enjeux stratégiques, dans les secteurs scientifique et économique (données de recherche).
« Il existe donc un risque d’accès par les autorités américaines aux données stockées »
Et dans le cas où les fournisseurs américains de ces outils prennent des mesures pour ne procéder à aucun transfert, de sorte de stocker et traiter les données en Europe ? Là aussi, il y a un problème : le Cloud Act. Ce texte autorise les juridictions à forcer les entreprises aux États-Unis de fournir les données sur leurs serveurs, dans le cadre d’une procédure, y compris les serveurs situés à l’étranger.
« Indépendamment de l’existence de transferts, les législations américaines s’appliquent aux données stockées par les sociétés états-uniennes en dehors de ce territoire. Il existe donc un risque d’accès par les autorités américaines aux données stockées », relève la Cnil. Dès lors, l’engagement de Microsoft en la matière doit être tempéré, même si la société a par le passé combattu ce genre de demande.
Pas de solution, sauf la migration ?
Enfin, si la Cnil admet qu’il faudrait déployer des mesures additionnelles pour poursuivre ces transferts même si le Privacy Shield est tombé, il s’avère que ces dispositions capables « d’assurer un niveau de protection adéquat » ne sont à ce jour pas identifiées. De plus, ajoute la Cnil, jouer la carte des dérogations n’est pas une réponse viable : elles doivent rester des dérogations, c’est-à-dire des exceptions.
Pour cette dernière remarque, la Cnil mentionne les observations du Comité européen de la protection des données, dont elle est membre, et qui raisonnait en citant soit le cas d’un fournisseur de services via le cloud soit le cas d’un sous-traitant qui « dans le cadre de leurs prestations, ont la nécessité d’accéder aux données en clair ou possèdent les clefs de chiffrement. »
Cette situation fait donc dire à la Cnil qu’il « est nécessaire que le risque d’un accès illégal par les autorités américaines à ces données soit écarté ». Mais parce qu’il n’est pas évident de basculer d’un claquement de doigts tout l’écosystème de l’enseignement supérieur et de la recherche, et parce qu’il existe encore une crise sanitaire à cause du coronavirus, la Cnil admet le besoin « d’une période transitoire. »
La Cnil se dit disponible pour « identifier des alternatives possibles ». Des pistes existent du côté des logiciels libres, à l’image de Framasoft ou LibreOffice. Il reste à déterminer quelles décisions seront prises à la suite de l’appel de la Cnil et, si l’offre est au niveau, car la commodité d’emploi, la disponibilité et l’éventail des fonctionnalités l’emportent parfois sur toute autre considération.
In the coming weeks, some Android users in the US on Chrome Canary may see an experimental Follow feature designed to help people get the latest content from sites they follow. Our goal for this feature is to allow people to follow the websites they care about, from the large publishers to the small neighborhood blogs, by tapping a Follow button in Chrome. When websites publish content, users can see updates from sites they have followed in a new Following section on the New Tab page:
Ces pécores sont en train de réinventer le flux RSS et les marques-pages dynamiques qui existaient dans Firefox déjà en 2005 (et que Mozilla a fini par virer dans les dernières versions pour faire comme Chrome).
Ça fait DIX ANS que Google tape sur le RSS pour le tuer à petit feu (en fermant Google Reader, supprimant les flux RSS de G+, cachant ceux sur Youtube, retirant leur détection de Chrome, et récemment bridant Feedburner…) c’était donc pour faire leur propre truc ?
Ne rêvez pas : c’est pas du XML/RSS qu’ils vont utiliser pour ça, mais probablement un truc basé sur AMP signé avec une clé API que les webmasters devront acheter, ou un autre système fermé du genre, qu’il faudra mettre sur son site, et que Chrome détectera s’il le veut bien (le tout filtré par par une pseudo-IA puritaine qui filtrera tout ce qui sort du copyreich, de la bienséance, et de bienpensance)
Chromium — à dissocier de Chrome — c’est peut-être open-source, libre avec des petites fleurs et tout, mais ça appartient à Google. Faudrait peut-être pas l’oublier : ce qui se trouve dans Chromium, c’est avant tout fait par et pour Google.
OpenStreetMap (OSM) est maintenant au centre d’une alliance contre nature des plus grandes et des plus riches entreprises technologiques au monde. Les sociétés les plus importantes au monde considèrent OSM comme une infrastructure critique pour certains des logiciels les plus utilisés jamais écrits. Les quatre sociétés du cercle restreint, Facebook, Apple, Amazon et Microsoft, se retrouvent maintenant à investir et à collaborer avec OSM à une échelle sans précédent.
The first time I spoke with Jennings Anderson, I couldn’t believe what he was telling me. I mean that genuinely — I did not believe him. He was a little incredulous about it himself. I felt like he was sharing an important secret with me that the world didn’t yet know.
If I write it here, I probably wrote it first on Twitter.
The open secret Jennings filled me in on is that OpenStreetMap (OSM) is now at the center of an unholy alliance of the world’s largest and wealthiest technology companies. The most valuable companies in the world are treating OSM as critical infrastructure for some of the most-used software ever written.
The four companies in the inner circle— Facebook, Apple, Amazon, and Microsoft— have a combined market capitalization of over six trillion dollars.¹ In almost every other setting, they are mortal enemies fighting expensive digital wars of attrition. Yet they now find themselves eagerly investing in and collaborating on OSM at an unprecedented scale (more on the scale later).
What likely started as a conversation in a British pub between grad students in 2004 has spiraled out of control into an invaluable, strategic, voluntarily-maintained data asset the wealthiest companies in the world can’t afford to replicate.
For the Uninitiated: What is OpenStreetMap?
I will admit that I used to think of OSM as little more than a virtuous hobby for over-educated Europeans living abroad — a cutesy internet collectivist experiment somewhere on the spectrum between eBird and Linux. It’s most commonly summarized with a variant of this analogy:
OSM is to an atlas as Wikipedia is to an encyclopedia.
OSM acolytes hate this comparison in the much same way baseball players resent when people describe the sport as “cricket for fat people.” While vaguely truthful, it doesn’t quite get to the spirit of the thing.
OSM is incomparable. Over 1.5M individuals have contributed data to it. It averages 4.5M changes per day.
You can think of OSM in several ways:
- A distributed community of mappers contributing information about the geography of the world to a common repository
- A free web map hosted at https://www.openstreetmap.org/
- A loosely affiliated collection of free and open source tools for mapping the world
- A real-time stream of instructions representing how to add, change, or remove cartographically projected geometries and associated metadata based on a prior state
- …Google Maps, but openly licensed
It’s hard to get people to agree on what exactly OSM is, but almost everyone agrees on one thing: it’s extraordinarily valuable and important.
What Jennings Told Me about OSM
For those paying attention, none of what I outline below will be news. However — outside of a relatively small cluster of weirdos who pay attention to trends in geospatial technology— almost no one seems to be paying attention.
That’s mostly because so few people have even heard of OpenStreetMap, despite the fact that hundreds of millions of people rely on it during any given month. If you’ve ever opened Snap Maps or Apple Maps or Bing Maps or even just peeked at the dash of your obnoxious neighbor’s new Tesla…you’ve used OSM.
In May of 2019, Jennings co-authored a paper with Dipto Sarkar and Leysia Palen titled, Corporate Editors in the Evolving Landscape of OpenStreetMap. If you prefer the research in presentation form, this talk is a fabulous summary of their findings:
Dr. Anderson’s talk at State of the Map 2019, “Corporate Editors in the Evolving Landscape of OpenStreetMap: A Close Investigation of the Impact to the Map & Community.”
In that talk, Jennings outlines the findings presented in his research. Not only was there already significant corporate investment happening in OSM in 2018, but in many cases corporate editors were responsible for the majority of edits in the specific geographies they were focused on. For instance:
For areas where corporate teams are active, on average, the non-corporate editors are now responsible for less than 25% of total road editing activity, which is down from closer to 70% in 2017.
Jennings noted, importantly, that as of 2018 non-corporate editors were still responsible for the majority of activity on OSM (about 70% of all edits) and were significantly more active on edits to buildings, places of interest, and amenities.
In a more recent talk from State of the Map in July 2020, Jennings presented updated figures showing that the torrent of corporate contributions only increased from 2018 to 2019 and beyond with Amazon and Apple trending along the steepest slope.
Seriously, watch the entire talk, it’s amazing: Curious Cases of Corporations in OpenStreetMap
Also interesting to note is Mapbox’s apparent decision to stop investing significantly into direct OSM edits and contributions. Apple was responsible for more edits in 2019 than Mapbox accounted for in its entire corporate history…I don’t have a good explanation for that. I wonder if they decided their effort could be more highly leveraged on core web mapping technology rather than manual digitization.
The Clash of Cultures Happening in OSM
I’m in no position to comment on most of the things I write about. But in this instance, I’m particularly unqualified — OSM has amassed a long-lived, fantastically diverse, and inherently fragmented community. I’ve never even commented in one of the forums.
But one thing that is clear even to a casual observer like me: one of the consequences of increased corporate involvement in OSM is a significant backlash from members within the OSM community that feel the community (and data) is being irreversibly adulterated by these profiteering intruders.
At the last OSM annual conference Frederik Ramm, a prominent and quite thoughtful OSM community member, summarized the attitude toward corporate contributors this way:
“[…] none of these companies is essential to OpenStreetMap. They are contributors, but OpenStreetMap could work perfectly well without them […] the mainstay of OpenStreetMap is the millions of hobbyists, individuals that contribute to OpenStreetMap.
A vocal minority of voluntary contributors to OSM seem to have a bit of a chip on their shoulder when it comes to the suits. A consistent undercurrent that I’ve noticed is skepticism about the motivations and incentives of for-profit firms. Here’s a typical sentiment excerpted from Serge Wroclawski’s magnificently controversial blog post, Why OpenStreetMap is in Serious Trouble (published in February of 2018).
Many of the founders of the project, as well as others, have launched commercial services around OSM. Unfortunately, this creates an incentive to keep the project small and limited in scope to map up the gap with commercial services which they can sell.
I think the playing field has changed significantly since Serge wrote those words — he was likely referring to projects like CloudMade (now defunct) and Mapbox ,which sought to offer generic map services on top of OSM’s dynamic map database (rather than enhance in-house products where mapping is ancillary to their core value proposition like it is for FAAM). He makes an interesting argument that OSM itself should be offering these services rather than letting companies piggyback on the efforts of countless volunteers while capturing all of the economic value.
What’s Motivating These Companies?
I wrote earlier this year about the concept of “Commoditizing Your Complement,” in my explanation of why Facebook acquired Mapillary and then gave away all the data they had just purchased for free.
The concept is simple: undermine your competitors’ intellectual property advantage by collaborating with aligned entities to cheapen it with a free and openly licensed alternative.
I would wager that corporate participation in OSM is less about directly monetizing souped-up versions of OSM data provided as modern web services and more about desperately avoiding the existential conflict of having to pay Google for the privilege of accessing their proprietary map data.⁵
Whatever the motivations of these mega-corporations, they’ve succeeded in carving out a niche for themselves within the OSM community whether the hobbyists like it or not. I’d like to highlight a nuance often lost in this discussion — just exactly who are these companies hiring to add data to the map? They are often already-active, enthusiastic contributors to OSM. These are people living the open data fanatic’s dream: getting paid to do a job they find so fulfilling they would otherwise do it for free in their spare time.
There’s obviously a lot more to it than just sticking it to Google. Facebook, for instance, has ambitions of building new types of digital experiences that interplay with the real world (as evidenced by their focus on augmented reality and acquisition of novel user interface technology like CTRL-labs). Apple has added LiDAR to its new line of iPhones and iPods allowing customers to scan the 3D world in high fidelity among other exciting uses:
These firms have outgrown your office and your living room. They want to be with you literally every where you go, and constantly seduce you with entertaining and immersive experiences. The more of your attention they can monopolize, the more money they can make from selling chunks of it to advertisers and people developing software on their platforms.
Whether you like their motivations or not, the result is a desire to map the world in higher fidelity and at larger scale than even they can afford to accomplish independently. And that has, for better or worse, brought their interests into alignment with the grassroots OSM community.
Why Does it Matter?
Well, anytime the wealthiest institutions in history are quietly collaborating on something, I think it’s worth noting. I’m not sure there is a precedent for such a collaboration — if you know of a case where otherwise embittered mega-corporations worked with a global community of volunteers on a public dataset…let me know. I’d love to learn about it.
The question on my mind is how idiosyncratic this situation really is. Does OSM represent a model for strategic corporate sponsorship of public goods moving forward? Or is it tragically inimitable?
For instance: I work for a company called Azavea that, among many noble efforts, maintains Cicero. It’s a database of elected officials and legislative districts in several countries around the world that gets updated daily. You can imagine that this should be a public good — like, doesn’t the government already have this information? Turns out…nah. Cicero requires ceaseless, grueling work to keep updated, and that means serious investment of time and money.
One of the key differences between Cicero and OSM is a community of contributors. Community is what makes OSM special. Without it, the project is “default dead,” as they say in Silicon Valley. Much like elected official information, map data goes stale fairly quickly and therefore requires constant life support.
OSM’s community seems conflicted about whether or not corporate participation is ok (let alone good) for the future of the project. And yet the community is precisely what attracts corporate contributors. OSM provides two advantages over just buying privately collected data:
-
Existing data is free and growing apace
- Proprietary data contributed to OSM may be expanded upon and/or maintained at no additional expense by the community
Some may squirm at the idea that their contributions to OSM help FAAM…after all, do they really need the help? But what’s beautiful is that FAAM is contributing (rather than passively mooching) because of the compounding value of having any/all data make it into the community’s growing number of hands.
I’m kind of shocked to be saying it, but somehow — almost inexplicably — the goals of the OSM community and corporate contributors seem to be largely aligned. They all want an accurate, ubiquitous map of the world that can be maintained in perpetuity as sustainably as possible.
It’s the opposite of the Tragedy of the Commons — all of the private property holders, acting in their own self interest, are enriching the common resource rather than depleting it.contributors account for ~90% of the edits to OSM. This roughly adheres to something called the 1% rule of online communities which states that, “1% of Internet users are responsible for creating content, while 99% are merely consumers of that content.”
Written by Joe Morrison
Le groupe chinois vient de perdre la dérogation à l'embargo américain qui lui permettait de maintenir à jour ses smartphones sous Android. Les anciens modèles ne devraient pas devenir obsolètes pour autant.
horizon s'assombrit pour les smartphones Huawei. Les États-Unis ont décidé d'accentuer encore un peu plus la pression sur le groupe technologique chinois. L'administration de Donald Trump n'a pas renouvelé la licence temporaire qu'elle accordait tous les trimestres à la firme de Shenzhen pour lui permettre de maintenir certains échanges avec des entreprises américaines depuis que le département américain du Commerce l'a placée sur une liste noire le 16 mai 2019 sur fond de guerre commerciale avec la Chine, selon le Washington Post.
À travers ces sursis, Washington souhaitait permettre aux entreprises technologiques américaines et aux opérateurs de télécommunications locaux de trouver des alternatives aux deals conclus avec Huawei, très implanté dans le secteur des télécoms outre-Atlantique. Ces accords permettaient notamment à Google de continuer à délivrer des mises à jour et des correctifs Android aux smartphones lancés par Huawei avant la mise en place de l'embargo. Contrairement aux appareils lancés après l'entrée en vigueur des sanctions, les anciens modèles pouvaient continuer à utiliser le magasin d'applications Play Store et les Google Mobile Services, les applications Google les plus populaires (Chrome, Gmail, Maps, Search, etc.), la pierre angulaire de l'expérience Android.
Depuis le 13 août, date de l'expiration de la dernière licence générale temporaire d'exploitation, Google ne peut plus collaborer avec Huawei. Les contours des conséquences de cette décision sont encore flous. En théorie, Google n'est désormais plus autorisé à fournir des mises à jour pour les appareils Huawei. Cela signifie que les anciens modèles de la marque et ceux de sa filiale Honor pourraient ne pas être mis à jour vers Android 11 dans les prochaines semaines. Des modèles comme le P20, le P30, le Mate 20 ou le Honor 10 pourraient cesser de recevoir les patchs de sécurité et les mises à jour pour les applications installées, avec le risque de devenir obsolètes.
Huawei continuera à proposer des mises à jour, mais...
En pratique, on ignore encore pour l'instant dans quelle mesure l'expiration de la licence générale temporaire impactera les futures mises à jour logicielles des smartphones des clients de la marque chinoise. Google a confirmé auprès du Washington Post que c'est bien cette licence qui lui permettait de collaborer avec Huawei et de prendre en charge les appareils lancés avant les sanctions américaines. Contacté par RTL.fr, un porte-parole de Huawei assure que les smartphones qui disposent déjà des applications Google continueront de les avoir et que des mises à jour vers la partie open source d'Android seront toujours déployées.
Huawei est en effet autorisé à utiliser la partie ouverte d'Android. Cette version accessible à tous les constructeurs n'est pas concernée par les restrictions américaine. Elle propose l'essentiel de l'expérience Android mais ne dispose pas des services Google et du magasin d'applications Play Store. C'est la version qui est déjà utilisée par Huawei pour ses smartphones lancés après la mise en place des sanctions, le Mate 30 et le P40. Sur ces modèles, on retrouve des mises à jour Android développées par Huawei via le système EMUI et des services alternatifs comme l'AppGallery, le magasin d'application de la marque (qui compte environ 60.000 références, une broutille par rapport au Play Store) et des applications maison, censées répondre aux mêmes besoins numériques que les applications Google, qui souffrent encore de la comparaison avec leurs concurrentes.
Huawei devrait logiquement s'appuyer sur ses équipes internes et sur la communauté open source pour continuer à proposer des mises à jour logicielles et de sécurité à ses clients. Ces dernières ne seront plus déployées directement par Google. Cela devrait rallonger de plusieurs semaines le délai de leur distribution. Avec un risque de voir des failles de sécurité exploitées par des cybercriminels dans cet intervalle, souligne le site technologique du quotidien belge Le Soir. Autre enjeu pour Huawei, réussir à maintenir à flot les services de Google et les applications les plus populaires du Play Store (Facebook, Instagram, Uber, etc.), sans l'aide de Google et des éditeurs américains de ces services, sous peine de les voir devenir peu à peu obsolètes, au fil des changements apportés dans leurs codes.
Les relations entre les USA et la Chine vont et viennent au gré des semaines et alors que l'on pensait les négociations au beau fixe avec une levée prochaine de l'embargo visant Huawei, voilà que les USA évoquent de nouvelles sanctions, encore plus lourdes.
Les efforts de Huawei pour se détacher de Google de façon définitive prennent un nouveau sens depuis quelques jours et l'annonce de probables nouvelles sanctions encore plus strictes émanant de la part des USA.
Depuis l'été dernier, les USA ont prononcé un embargo sur la marque chinoise, accusée d'utiliser ses dispositifs de télécommunications pour organiser un espionnage au profit de Pékin, et ce, à travers le monde. En conséquence, certaines sociétés américaines n'ont plus l'autorisation de collaborer avec la marque, et si certaines sanctions ont été levées, la plus importante concerne Google et l'intégration des services mobiles du groupe américain dans les smartphones de Huawei.
Huawei P30 Pro_35
Face à la situation, Huawei a réagi et développe ses propres alternatives, décidé à s'émanciper du bon vouloir américain pour continuer à développer ses parts de marché... Mais les USA pourraient aller beaucoup plus loin pour stopper net la marque sur le terrain du smartphone.
Dans des propositions de nouvelles sanctions, il est évoqué un amendement qui permettrait aux USA de contraindre Huawei à ne plus se fournir de composants ou services quand ces derniers intègrent plus de 10 de propriétés intellectuelles américaines.
Mais la mesure pourrait aller encore plus loin : les USA pourraient tout simplement contraindre les sociétés qui exploitent du matériel américain ou des licences américaines à ne plus collaborer du tout avec Huawei, sous peine de se voir retirer les licences d'exploitation ou le matériel en question.
Huawei P30 Pro_37
Le problème est donc le suivant : même si Huawei dispose de ses propres SoC, la marque ne les produit pas elle-même et c'est le fondeur TSMC qui s'en charge à Taïwan. Or, TSMC utilise en grande majorité du matériel américain dans ses processus de fabrication, et aucune chaine de production ne mise sur du matériel 100% chinois...
En clair, les USA pourraient trouver là un moyen de pression permettant de priver Huawei du moindre composant électronique et assécher ainsi sa production de smartphone.
Il est actuellement très difficile de penser que les USA pourraient aller jusque là dans sa guerre commerciale avec la Chine, qui par ailleurs pourrait appliquer des conditions similaires dans une foule d'autres domaines. Cette alternative pourrait d'ailleurs déclencher une véritable cascade de mesures protectionnistes à travers le monde entier et ce ne sont certainement pas les meilleurs leviers à pousser d'un point de vue diplomatique ou économique, mais comme toujours avec les USA, il est avant tout question d'intimidation.
Toujours sanctionné par l'embargo américain, Huawei n'est pas en mesure de proposer l'accès aux Google Mobile Services sur ses terminaux. Et selon un cadre de la marque, la situation ne changera pas, même si les USA levaient les sanctions.
Mise à jour du 31/01/2020
Huawei a tenu à apporter une précision supplémentaire en réponse à notre article : "Une version libre de droit du système d’exploitation et de l’écosystème Android reste notre préférence, cependant si nous ne pouvions pas continuer de l’utiliser, nous avons la capacité à développer nos propres système d’exploitation et écosystème"
Article d'origine :
Huawei est sans doute allé trop loin pour faire machine arrière désormais : un cadre de la marque chinoise affirme ainsi que la marque ne souhaite plus réintégrer les services de Google dans ses terminaux, même si la levée de l'embargo américain était prononcée.
Cela fait des mois que la situation stagne : depuis la fin du mois de mai 2019, Huawei a été placée par décret sur la liste noire des sociétés chinoises avec lesquelles les marques américaines ne peuvent plus collaborer. Si quelques assouplissements ont eu lieu depuis, Huawei n'est plus en mesure d'utiliser la version d'Android de Google, ni ses services. Cela implique aucun accès au Play Store, Gmail, Maps et autres produits signés Google.
Si le marché asiatique est de toute façon peu intéressé par les services de Google, la marque règne sans partage sur l'Europe et le reste du monde, et Huawei a été déstabilisé par la situation.
Mais la marque s'est rapidement tournée vers Android AOSP, et lancé un plan d'investissement colossal pour attirer les éditeurs et développeurs sur sa propre plateforme : Huawei App Galerie.
La situation reste assez problématique pour les utilisateurs, et pourtant Huawei ne souhaiterait plus faire machine arrière : selon un cadre de la marque, le géant chinois a trop investi pour revenir sur les services de Google, et la situation a été vécue comme un élément déclencheur pour initialiser l'émancipation de la marque vis-à-vis des USA.
Huawei P30 Pro_35
Le Mate 30 Pro, premier smartphone de Huawei à sortir sans services Google
Huawei ne veut plus être dépendante de Google, et plus que cela, la marque souhaite désormais se poser en concurrence directe : Huawei pourrait ainsi proposer ses propres services à tout un ensemble d'autres marques asiatiques pour doper l'adoption de ses outils.
Même si l'embargo américain vient à être levé, rien n'indique qu'une nouvelle sanction n'interviendra pas d'ici 1 an ou même plus rapidement et Huawei ne souhaite plus être suspendue aux décisions politiques de la sorte.
La marque reste réaliste et s'attend à une baisse des parts de marché sur l'année : la gamme P40 ne proposera pas les GSM, et il faudra du temps aux utilisateurs et beaucoup de communication pour faire valoir les alternatives de la marque.
Du fait de la bataille commerciale entre Washington et Pékin, Huawei ne peut pas proposer l'écosystème logiciel de Google dans ses nouveaux smartphones. Le groupe chinois a donc dû trouver une parade, en signant un accord avec la société néerlandaise TomTom pour remplacer Google Maps.
C’est un effet très visible de la guerre commerciale qui se joue entre les États-Unis et la Chine et dont Huawei est une victime indirecte. Parce que Washington a décrété que l’entreprise chinoise constitue une menace pour la sécurité nationale, ses homologues aux USA ne peuvent plus faire des affaires librement avec elle. Ainsi, les smartphones à venir de Huawei doivent composer sans les services de Google.
Concrètement, cela veut dire que les nouveaux modèles de Huawei ne peuvent plus avoir accès à des applications qui sont entrées dans les usages quotidiens d’un très grand nombre de mobinautes, qu’il s’agisse de Gmail pour le courrier électronique, YouTube pour le visionnage de vidéos ou bien Maps pour bénéficier d’une solution de cartographie pour se repérer dans l’espace.
Ayant perdu l’accès à l’écosystème logiciel de Google, le géant chinois des télécoms doit changer de fusil d’épaule. Une première réponse est arrivée l’an dernier, avec le souhait de Huawei de bâtir un environnement libéré de futurs coups du sort de ce genre. Signe de ce plan, certains terminaux récents de la marque n’intègrent plus aucun composant d’origine américaine.
Huawei signe avec TomTom
Depuis, une autre réponse a émergé : celle des partenariats avec des fournisseurs tiers, qui ne sont pas américains. Le 17 janvier, Huawei a annoncé un partenariat avec TomTom, une société néerlandaise bien connue du grand public pour ses systèmes de navigation GPS, à accrocher à l’intérieur de la voiture ou à télécharger sur son smartphone, notamment sur ceux fonctionnant avec… Android.
Selon un porte-parole du groupe, le deal entre TomTom et Huawei n’est pas tout à fait récent — il était toutefois tenu secret, pour une raison qui n’a pas été donnée. Les détails financiers de cet accord ne sont pas non plus précisés, mais ils sont vraisemblablement favorables à TomTom, qui va de fait bénéficier de l’exposition de son partenaire — qui est l’un des principaux fabricants de smartphones — pour toucher davantage de clients.
Une alternative qu’aurait pu envisager Huawei, c’est OpenStreetMap. Il s’agit d’une sorte de Google Maps, mais reposant sur une base de données libre et coopérative. D’autant que Huawei a les moyens d’investir dans le développement du projet pour combler ses éventuels manques, en y déployant des ressources. Peut-être cela aurait-il été plus économique, d’ailleurs, qu’un deal avec TomTom.
Cela étant, peut-être que pour des questions évidentes de calendrier, Huawei avait surtout à cœur d’aller vite et la solution de TomTom s’avérait peut-être un choix plus judicieux pour pouvoir proposer tout de suite une alternative à Google Maps. Après tout, TomTom reste un outil de cartographie de bonne facture, en témoigne sa présence comme logiciel embarqué dans certains véhicules de premier plan.
Sans aucun consentement de la part des patients, Google a récupéré en toute discrétion des millions de données médicales aux USA.
C'est un nouveau scandale qui s'annonce : le Wall Street Journal et Forbes évoquent dans leurs colonnes que Google aurait mis la main sur "des données médicales de millions d'Américains à travers 21 États" sans avoir obtenu le consentement des patients.
Car il ne s'agit pas là de données récoltées par l'application Google Fit de la marque, mais de données véritablement sensibles récupérées à travers un partenariat noué avec un assureur privé. Les données sont issues du projet Nightingale et proviennent de laboratoires, de médecins ou d'hôpitaux. Pour certains patients, les données correspondraient à l'historique complet de santé intégrant leur nom, date de naissance...
C'est Ascension, un assureur privé aux États-Unis qui a partagé ces informations avec Google. Le partenariat permet à Google d'accéder aux données des assurés pour développer et proposer un outil permettant à ces derniers de mieux retrouver les données des patients à l'aide d'un moteur de recherche doté d'intelligence artificielle.
Malgré tout, la situation pose un sérieux problème sur la capacité de Google à gérer ces données sensibles et à y avoir accès notamment parce que les médecins et patients n'ont jamais donné leur accord. Par ailleurs, 150 salariés de Google auraient eu accès à ces données pour un traitement manuel.
Pointé du doigt, Google tente de désamorcer la situation en expliquant sur son blog avoir obtenu les autorisations nécessaires et précise que les données en questions sont par ailleurs déjà partagées par l'assureur pour d'autres objectifs. Google assure ne pas stocker les données de son côté... Reste à savoir si l'explication sera suffisante pour les concernés.
Théoriquement, on ne peut transférer les mails de Google que vers une seule adresse. Si on en ajoute une deuxième, elle remplacera la première dans la configuration, même si elle reste dans un menu déroulant, et qu'on y a accès pour la reconfigurer comme adresse de transfert.
Mais Google nous précise qu'avec le système de filtre, on peut envoyer "certains" emails vers une autre adresse.
Donc, on construit un filtre (dans les paramètres de l'onglet Transfert de Gmail, le lien est au bas de la première section) en sélectionnant les mails avec le minimums de contraintes, voir aucune (indiquer seulement que le destinataire est l'adresse email et tous les emails reçus seront dans la sélection) et ... tada, on peut envoyer les mails vers une 2e adresse aussi.
Résumé de l'article en anglais disponible en cliquant sur le titre de ce billet.
Note de Kat : Google nous a rendus dépendants de son hébergement gratuit pour nos mails depuis des années. Maintenant, Google va nous le faire PAYER. Gmail restreint l'espace disponible en quantité et en qualité, interdisant aussi de nombreuse pièces jointes. Cela a coïncidé avec le lancement de son nouveau service PAYANT de cloud. Mais c'est pas nouveau toussa, j'en causais déjà il y a 2 ans, là, sur le forum de TechniFree : http://technifree.fr/modules/newbb/viewtopic.php?topic_id=2113
Ce qui est nouveau, c'est que ça touche maintenant de plus en plus de gens qui ont atteint leur quota, alors qu'ils avaient misé toute leur communication sur Gmail.
Nous ne voulons pas que Google nous paie pour enrichir les liens qu'il référence. Alors que les voix qui soutiennent cette redevance n'ont jamais été aussi fortes et médiatisées, Numerama a choisi d'expliquer les raisons pour lesquelles nous trouvons qu'elle est absurde.
L’économie des médias est un sujet qui n’entre pas exactement dans notre ligne éditoriale. Par la force des choses, étant un média 100 % indépendant qui vit du web et rémunère 8 journalistes en CDI à temps plein, dans une entreprise qui en compte une trentaine, nous pratiquons en revanche cette économie au quotidien. Depuis la massification du numérique, la presse se dit très souvent en crise. Crise d’audience, crise de revenus, crise de technique, crise de format, crise de légitimité, crise de confiance.
Dans un premier temps, le discours alarmiste cherchait à enclencher un cycle de transformation des médias, ce qui est positif : les esprits cogitent quand ils sont menacés. Ces derniers temps, il cherche surtout à trouver des coupables quand la transformation numérique ne s’est pas faite.
La dépêche, traduite en anglais et poussée
Le 22 octobre, une « lettre ouverte » signée par des centaines de journalistes a été publiée et relayée massivement par l’AFP, plaçant sa dépêche en copier-coller chez tous les médias partenaires. La cible ? Google. Google, pointé du doigt pour avoir trouvé comment éviter de payer la presse pour référencer ses liens dans le moteur de recherche, les applications liées à Google News et à Discover. Cette « lettre ouverte » est la continuité d’une campagne de lobbying au niveau européen, menée de longue date et ayant abouti à la Directive droit d’auteur, dans laquelle plusieurs médias, AFP en tête, sont juges et partis. Cette position a été pointée du doigt par l’ancienne députée Julia Reda pour son manque de déontologie : sous couvert d’information neutre, ces médias créent ou relaient un discours à sens unique, qui se permet en plus, bien souvent d’englober toute la presse européenne dans un grand navire en lutte contre des ennemis imaginaires.
En tant que média, Numerama s’est contenté d’expliquer tour à tour les dangers de cette loi pour le web, l’inutilité de ses contours légaux, mais a aussi relayé les critiques adressés par cette presse aux géants du web — qui sont loin d’être toutes illégitimes. Nous estimons que pour nos lectrices et nos lecteurs, nous avons fait notre travail d’information.
Aujourd’hui, comme la parole est subtilisée et projetée de manière démesurée par les anti-référencement sur Google, jusqu’à nous inclure dans des formulations englobantes, nous avons décidé de communiquer sur notre position et nos choix.
Le référencement sur Google est bénéfique
Être anti-Google est à la mode. Ajouter « contre les GAFA » dans un business plan permet d’augmenter une levée de fonds de quelques euros. Proposer des services technologiquement dépassés pour être contre est acclamé, relayé, encensé parfois par la classe politique. C’est une posture reprise récemment par la presse qui a un ennemi tout trouvé, volant à la fois ses audiences, ses revenus publicitaires… et son contenu.
Pour nous, cette position est intenable. Sans verser dans la caricature, nous ne pouvons que nous rappeler à quel point le web que nous connaissons doit à Google — et à l’indexation des contenus de manière générale. Pour notre média, Google est un kiosque imparfait mais vertueux, avec une puissance que peu d’entités ont eu auparavant dans l’histoire de la presse. Il nous permet tout à la fois d’inscrire nos articles dans une temporalité longue par du référencement naturel, mettre en avant nos articles dans des outils comme Google News ou pousser des sujets aux lectrices et aux lecteurs sur Android et iOS. Et, grosso modo, Google fait plutôt bien son travail, qui consiste à amener la personne en quête d’information vers un article répondant à son interrogation.
C’est pour cela que, depuis de nombreuses années, ce jeu est bénéfique pour nos médias. Comment accepter l’absurdité de croire que mieux renseigner des lecteurs potentiels sur le contenu de l’article qu’ils vont voir après le clic serait négatif pour nous ? Les expérimentations de Google dans le moteur de recherche ont toutes cette finalité : non seulement amener rapidement vers un article de presse pertinent, mais aussi, informer au maximum sur la pertinence du clic.
Et c’est pour cela que nous sommes heureux de fournir des éléments à Google et aux autres moteurs de recherche sur le contenu de nos papiers : titre, image de une, description, accès aux rubriquage, parfois questions en FAQ, graphiques, tableaux. Nous craindrons en réalité le jour où Google nous demandera de payer pour ce travail de référencement gratuit, qui nous amène audience et, mécaniquement, revenus — ce qui vaut aussi bien pour les modèles de presse gratuite que pour les modèles sur abonnement.
Qui pourrait penser fournir une version de son magazine à un kiosquier physique dénuée de toute information, de toute rubrique, de toute image de couverture, avec simplement le titre du média ? Qui, ce faisant, oserait demander au kiosquier une redevance par élément figurant sur la une ? Personne. Et pourtant, c’est ce que cette presse demande à Google : payer la presse pour permettre de rémunérer la presse, sous couvert d’une lutte anti-GAFA bien pratique pour politiser le message.
Ce que Numerama refuse catégoriquement, tant les problèmes générés seraient dangereux.
Masquer les enjeux réels
Ce discours est une manière de mettre sous le tapis les problèmes soulevés par le numérique et la presse au numérique. L’AFP, en tête de file de la contestation, n’a pas cru bon de changer son business model reposant sur la vente de dépêches aux autres médias, qui copient-collent à outrance des textes écrits par les journalistes de l’agence, retouchant souvent maigrement le contenu. Le web n’aime pas le contenu dupliqué (duplicate content), Google non plus (et les jeunes journalistes dégoûtés du métier à cause du batonnage non plus, mais c’est une autre histoire) : un contenu répété tel quel sur des dizaines de médias perd de sa valeur pour un moteur de recherche. C’est une chose sue depuis 20 ans : l’AFP n’avait-elle pas l’occasion de penser à sa transformation économique pour coller aux nouveaux enjeux du numérique ?
Pour ces médias habitués aux intraveineuses de subventions publiques, faire payer pour des liens hypertexte (constituante technique du web qui a une valeur inestimable de citation et de maillage de « la toile ») est une manière de continuer à faire ce qu’ils font de longue date, sans se remettre en question. Ils ne voient pas le problème à greffer un modèle économique sur un fait technique, qu’ils maîtrisent d’ailleurs souvent mal : nous ne comptons plus les fois où nos articles originaux ou enquêtes exclusives sont repris sans lien — même si certains confrères et consœurs sont irréprochables en la matière, et nous les en remercions.
De la même manière, rémunérer la presse pour du référencement augmenté inscrit une différenciation entre un site web et un site web d’information. Et entre les deux, la frontière est parfois ténue : aux États-Unis, la section recettes du New York Times est plébiscitée par ses lecteurs et ses lectrices. Est-ce de la presse ? Et Marmiton, est-ce de la presse ? Faut-il dès lors rémunérer le journal pour la même typologie de contenu que le « site web » ? Google a raison quand il dit qu’il ne faut pas se risquer à créer une relation commerciale pour le référencement naturel, qu’importe l’acteur avec qui il négocie : ce n’est pas son rôle, c’est celui des espaces publicitaires qui apparaissent avant les résultats.
L’insistance de la presse après le refus de Google de payer est tout aussi problématique : elle montre que sa seule préoccupation est d’être rémunérée d’une manière ou d’une autre pour être référencée. Aujourd’hui, la solution de Google a été de dire que le référencement ne serait pas touché par la décision, ou non, de transmettre des informations supplémentaires pour enrichir les résultats. Demain, Google pourrait tout simplement proposer d’arrêter de référencer le contenu des médias… qui dépendent, sur le web, massivement de Google pour exister. Économiquement, la fermeture de Google News en Espagne a été néfaste pour les médias : une leçon que ni l’Europe, ni la France, ne semblent retenir.
La dépendance des audiences à Google n’est pas le problème que la presse souhaite régler
Cette dépendance du lectorat européen à Google est un vrai problème, mais ce n’est, encore une fois, pas celui que la presse a choisi de régler. D’autres acteurs, plus malins et plus en phase avec les attentes de nos lectorats, s’en chargent : Apple a son Apple News, Samsung a Upday et les agrégateurs, parfois de grande qualité, ont un terrain de choix à occuper. La presse est encore passée à côté d’une opportunité et ces business construisent intelligemment la fin (même si relative) de l’hégémonie de Google pour accéder aux articles.
Pour résumer notre position, nous pensons que vouloir faire payer Google pour des absurdités liées au référencement est une très mauvaise idée pour la presse en ligne. La Directive droit d’auteur est d’ailleurs si mauvaise et si peu adaptée aux enjeux modernes que Google peut refuser légalement de payer une redevance en incluant un opt-in — beaucoup de médias, ceux du groupe Humanoid inclus, sont d’ailleurs déjà prêts, d’après Mind News.
Plutôt que de demander rémunération pour justifier l’immobilisme, nous appelons la presse à se poser les bonnes questions pour se transformer efficacement et envisager un avenir où Google n’est qu’un cadre de plus pour référencer du journalisme de qualité.
Google référence mal ? Regardons comment, et où sont distribués nos contenus. Google a pris des revenus publicitaires ? Le Nieman Lab a montré à quel point imputer ces pertes aux géants du web était ridicule : réfléchissons plutôt à la manière dont fonctionne notre rémunération et la monétisation de nos espaces publicitaires. Google gagne de l’argent avec notre travail ? Ce n’est que marginalement vrai : Google gagne de l’argent en affichant de la publicité à ses utilisateurs. Si nos articles ne sont plus dans Google, d’autres, peut-être moins bons, prendront leur place — Discover et Actualités n’ont pas d’espace publicitaires associés.
Alors si demain, la question nous est posée de savoir si nous souhaitons être mis dans le même panier que la presse et disparaître des moteurs de recherche ou être sortis de cette case pour continuer à proposer le contenu que nous espérons de qualité à toujours plus de lectrices et de lecteurs, nous prendrons la deuxième option avec regret. Regret que « la presse » avec laquelle nous partageons tant de valeur se soit tirée une balle dans le pied et qui, par ricochet, ait touché aussi celles et ceux qui voyaient la catastrophe arriver et tentaient de mettre en garde.
Contrairement à de nombreux médias, Numerama ne touche ni subvention publique, ni subvention privée, n’a pas touché d’argent du Fonds Google (DNI) ou des initiatives similaires portées par d’autres géants du web pour accompagner la transformation numérique des publications en ligne. Numerama est présent sur Google News, Upday, Squid, Flipboard et d’autres agrégateurs avec lesquels nous avons des partenariats — non rémunérés — de diffusion.
Les éditeurs de presse se rebiffent contre le Google et ses règles pour s'adapter à la création d'un droit voisin. Même s'ils sont largement obligés de les accepter.
C'est aujourd'hui que la transposition de la directive européenne créant un droit voisin pour des agences et éditeurs de presse est entrée en vigueur en France. Une date symbolique qui donne lieu à des représailles.
Pour se mettre en conformité, Google a fait le choix avec les résultats de recherches de ne pas afficher par défaut des aperçus d'articles avec quelques lignes ou les petites images. Les éditeurs et agences de presse peuvent donner l'autorisation d'afficher des contenus enrichis, mais sans rémunération en contrepartie.
De la sorte, Google se soustrait à un paiement pour des droits voisins. Pour cette adaptation à la nouvelle législation, des critiques ont fusé en estimant qu'elle bafoue l'esprit de la directive européenne. Le ministre de la Culture avait appelé à " une véritable négociation globale entre Google et les éditeurs. "
Résultat… les éditeurs de presse français ont décidé de porter plainte contre Google devant l'Autorité de la concurrence pour abus de position dominante.
Google a un levier fort à sa disposition. Son moteur de recherche est un important pourvoyeur de trafic et c'est pour cela que des éditeurs de presse ont finalement accepté que leurs extraits soient utilisés gratuitement.
Aux Échos, Marc Feuillée, directeur général du Figaro, président du Syndicat de la presse quotidienne nationale et vice-président de l'Alliance de la presse d'information générale, déclare : " L'Autorité de la concurrence doit faire cesser cet abus. Il est nécessaire de prendre des mesures conservatoires pour aller vite car il faut tout stopper, avant que la situation ne devienne irréversible. "
Du point de vue de Google, c'est un service gratuit qui est offert aux éditeurs de presse pour leur permettre de générer du trafic en aiguillant les internautes et leur permettant d'attirer un nouveau public.